这个专项课程一共五门,包括
- Neural Networks and Deep Learning(神经网络与深度学习)
- Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and Optimization(改进深度神经网络:超参数、正则化和优化)
- Structuring Machine Learning Projects(构建机器学习项目)
- Convolution Neural Networks(卷积神经网络)
- Sequence Model(序列模型)
Structuring Machine Learning Projects 学习笔记
第三门课程主要介绍Machine Learning的一些模型评估方法。
- Introduction to ML Strategy
- Setting up your goal
- Comparing to Human level performance
- Error Analysis
- Mismatched training and dev/test set
- Learing from multiple tasks
- End to End deep learning
在使用机器学习模型训练模型遇到问题时,我们可能会有以下一些想法。但是我们并不能确定哪个能够改善我们的模型,本课程主要就是分析在哪些情况下使用哪些方法比较好。

Orthogonalization
-
正交化的思想可以看作设计旋钮(knobs)时,每个旋钮只控制一件事。
-
在ML项目中如何使用“正交化”优化我们的思考过程呢?在ML项目中我们主要要完善四个问题:
- Fit training set well on cost function, 否则我们需要bigger network, Adam……
- Fit dev set well on cost function, 否则我们需要Regularization, Bigger training set……
- Fit test set well on cost function, 否则我们需要bigger dev set……
- Performs well in real world, 否则我们需要改变dev set或是cost function
上面我们谈到的Fit well on cost function指的是达到Human level performance.
Setting up your goal
Single number evaluation metric (单一量化评估指标)
对学习模型的泛化能力进行评估,需要有衡量模型泛化能力的指标,也就是性能度量。这里我们使用🍉西瓜书中一套符号来表示下面的概念。
| 预测为正例 Positive | 预测为反例 Negative | |
|---|---|---|
| 实际为正例 | TP(真正例) | FN(假反例) |
| 实际为反例 | FP(假正例) | TN(真反例) |
-
Precision(准确率,查准率)——总样本为预测为正例
-
Recall(召回率,查全率)——总样本为实际为正例
-
F1 score——Precision和Recall的调和平均
-
在机器学习模型的迭代过程中,一个好的dev set(用来测量P和R)加上单一量化评估指标(singal real number evaluation metric)可以大大加快iterating的速度。
Satisfy and Optimizing metric(受限指标和优化指标)
在机器学习模型中会有很多指标(metrics),一般有一个Optimizing metric(优化指标)和其它一些Satisfy metric(受限指标),即在满足受限指标的条件下,调节优化指标达到最佳的效果。下面举两个栗子:
-
针对一个classifier,我们有两个指标:accuracy(准确率)和Running time(运算时间),我们需要
即在运行时间小于100 ms前提下,最大化准确率。在这个问题中,准确率就是一个优化指标,运行时间是一个受限指标。
-
针对智能助手的唤醒词(wake word/ Trigger word),有两个指标:accuracy(准确率)和False Positive次数,我们需要
在这个问题中,准确率就是一个优化指标,False Positive次数是一个受限指标。
Train/ dev / test set(训练集、验证集、测试集)
- Train/ dev / test set的分布
在第二门课程中已经谈到过这三个集合,这里再次强调- Development and test sets come from same distribution.
- 我们需要从两方面考虑选择Dev set和test sets,即在未来你希望在哪些数据上有所体现,或是你认为重要的一些方面。
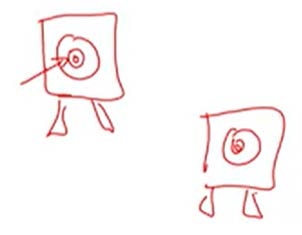
- 下面的图像很生动地显示出了未好好选择Dev set和test sets的后果:类似于射箭,在测试时你要求射中左上角的靶子,而在实际应用中却要求射中右下角的靶子,这是现在不切实际的。
![target]()
- Size of dev/ test set
这个问题也在第二门中谈到过了。一般我们选取较多数据作为train set,较少的数据作为dev和test set。这里主要强调的是test set。- 虽然我们只选择很少的一部分作为测试集,但是既然选取了测试集,我们需要保证测试集的数量足够多,能够支撑起对于整个模型的评价,且有较高的置信度。
- 但是没有测试集也是可以的。
- 在学习模型中,training set用于训练模型,dev set用于调节(tune)模型参数,test set用于评估模型最后的cost。
When to change dev/test sets and metrics
-
假设有两个分类器:
指标 错误率 问题 A 3% 出现了porn graphic B 5% 从指标上看来,A分类器仿佛更好,但是从主观来说我们不希望出现porn graphic,会更倾向于B。所以很容易想到,我们需要对出现porn graphic这种情况加大惩罚,所以我们采用一个单独的参数来表征
而我们的cost function也就变为
起到了惩罚出现porn图片的作用。
-
同时我们也可以从“正交化”的角度来防止出现porn
- 定义一个新的指标(是否porn)用来评价分类器👉
放置了一个靶子 - 单独考虑模型是否在这个指标上做的好不好👉
射击靶子
- 定义一个新的指标(是否porn)用来评价分类器👉
-
如果模型在你的指标在验证集、测试集做得很好,但是当真正落地到应用上时并不好,这就说明你的指标或是验证集、测试集可能存在问题,需要更换。
Comparing to Human level performance
Human level performance & Avoidable bias
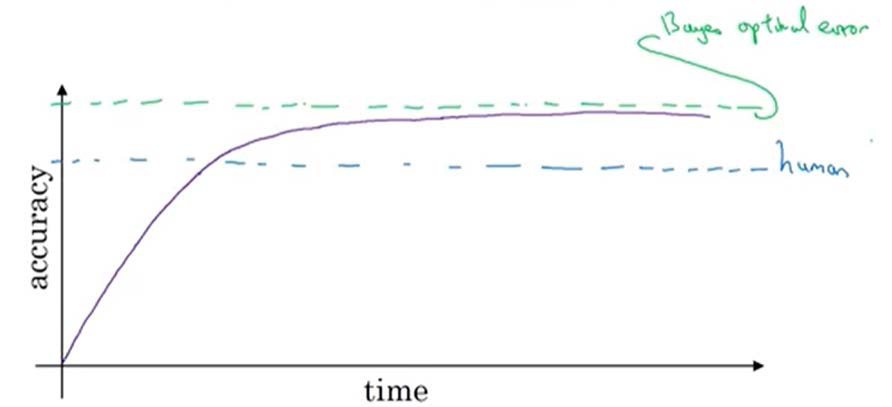
- 人们在处理很多事情时都很有优势,当模型比人类水准差时,你需要考虑:
- 通过人手动获取标签
- 从人的角度来思考为什么错了?为什么人能分辨出来?
- 对于bias和variance进一步分析
- 一般我们将Human level performance(人类水准)作为Bayes optimal error(贝叶斯误差)的近似估计。
- 当出现下面情况时,误差一般是能被避免的
- 人类水准←→训练误差(train error)相差大:专注于bias
- 训练误差←→验证误差(dev error)相差大:专注于variance
- 如何定义人类水准(human-level performance)?我们将人类水准定义为最有经验的一群人的误差,一般。
![error_ecample]()
- People are good at natural perception.

Improving your model performance
- 监督学习(supervised learning)的两个基本假设:
- 训练集很好地符合要求(Avoidable bias)
- 训练集的表现很好的概括了验证集和测试集的特征(variance)
- 抑制bias和variance的方法
![抑制bias和variance的方法]()

Error Analysis
模型可能会出现的错误
- Look at der examples to evaluate ideas
- 从mislabeled dev set中⼿动数可以处理的照⽚,根据此确定如何处理
- 考虑什么是重要的?
- Evaluate multiple ideas in parallel
在一个猫的分类器中,可能会出现这些错误:把狗、猫科动物当作猫,因为模糊而导致误判,我们通过列表可以并行手动识别问题,并根据比例处理这些问题。
![Evaluate multiple ideas in parallel]()

数据中可能出现的错误
- DL算法对训练集中的随机错误是比较稳健的,但是对于系统性错误鲁棒性就比较差。
- 在验证集和测试集中误标注标签的数据:通过列表来处理,同时要注意每种错误标签的占比
- Correcting incorrect dev/ test set example的步骤:
- 对你的验证集和测试集应用同样的过程,以确保它们继续来自相同的分布。
- 考虑检查你的算法所做的正确和错误的例子
- 此时,训练和验证/测试数据现在可能来自稍微不同的分布
Build your first system quickly, then iterate
一般地,建议尽快建立模型,并开始迭代,在迭代中再去改进模型。一个系统的基本运作过程如下:
- 设立验证集、测试集和评价指标
- 快速建立初始的系统
- 使用bias/variance分析和error分析确定下一步的优先次序
Mismatched training and dev/test set
Training and Testing a different distribution
有时候获取来自同一分布的大量数据很难,我们需要使用一部分其他分布的数据,那么如何在训练、验证、测试集中分配这两部分的数据。下面有两个例子:
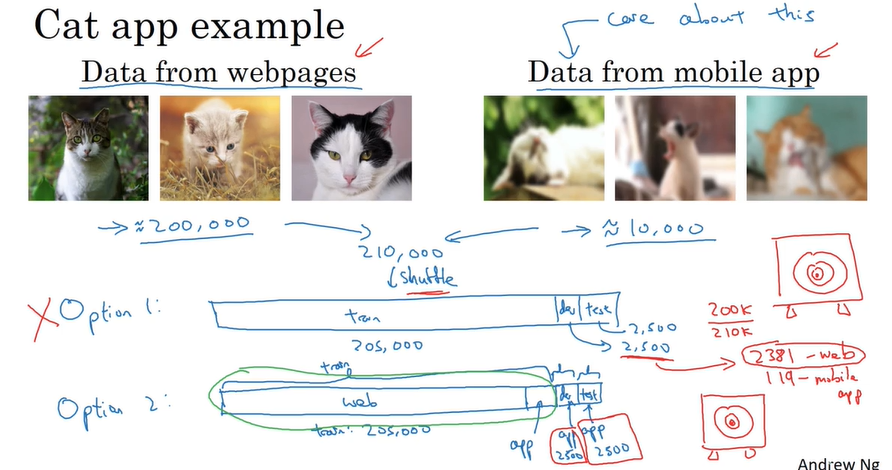
注意我们不能将同一分布、不同分布的数据合并,平均分配到训练、验证、测试集中去,而应该有倾向性地将同一分布的数据分配到验证集和测试集。
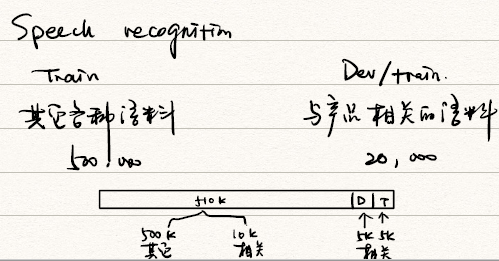
Bias and Variance with mismatched data distribution
-
利用Training-dev set
![Training-dev set]()
- 和训练集来自同一分布
- 不被用于训练
下面通过一组数据来了解如何利用Training-dev set分辨Bias and Variance从而处理数据来自不同分布地情况。
![Training-dev set2]()
-
更一般的情况
![更一般的情况]()


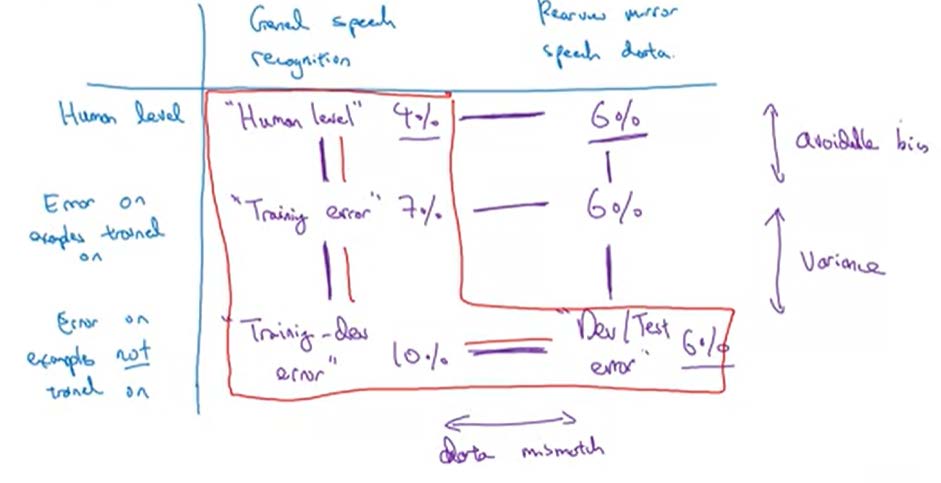
Addressing data mismatch
- 手工处理👉需要了解训练集和验证、测试集之间的不同到底导致哪方面的问题
- 使得训练集更类似类似于验证、测试集即收集更多类似的数据
- 但在手工处理时,需要防止NN适应了重复性的元素,从而带来过拟合
Learning from multiple tasks
Transfer learning
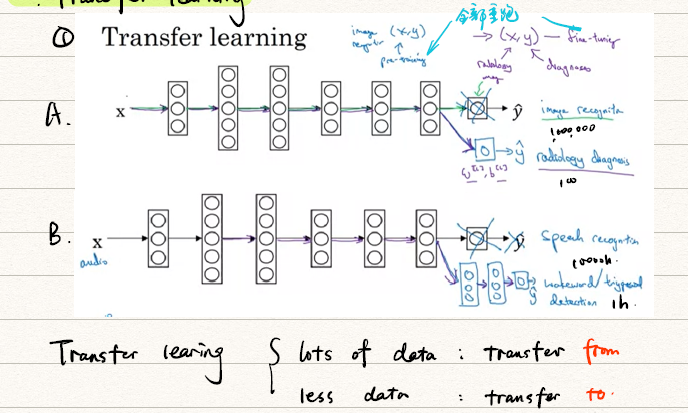
何时可以用Transfer learning?
- 任务A和B的输入是一致的
- 相比于任务B,任务A有更多的数据
Multi-task learning
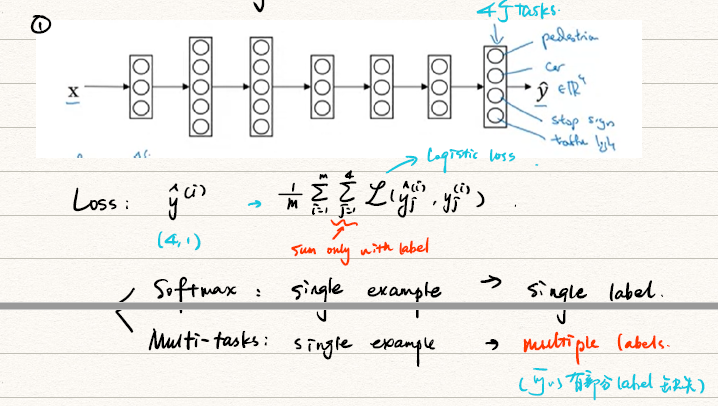
何时可以用Multi-task learning?
- 在一组任务上进行训练,可以从有共享的低级特征可以从中受益。
- 通常情况下,每个任务的数据量是相似的。
- 可以训练一个足够大的NN,以便在所有的任务中表现良好。
- 这在第四门CNN的目标识别中经常使用。
End to End DL
当一个问题有很多步骤来处理时,我们可以把整个过程看作一个黑箱,作为一个神经网络,这就是端到端学习(end-to-end deep learning)。
-
优点:
- 让数据“说话”
- 手工处理的部分很少
-
缺点:
- 可能需要大量的数据
- 可能缺少了一些有益的手工处理,但是在黑箱中我们没法处理
-
在使用end-to-end deep learning时,我们需要考虑是否有充足的数据来实现一个足够复杂的从的映射。
-
应对方法:
- 使用DL学习一个个小子块;
- 仔细选择的映射,以保证你可以获得充足的数据
参考文献
- 周志华著. 机器学习. 北京:清华大学出版社, 2016.01.
